
JVM那些事儿
1.JVM总体框架
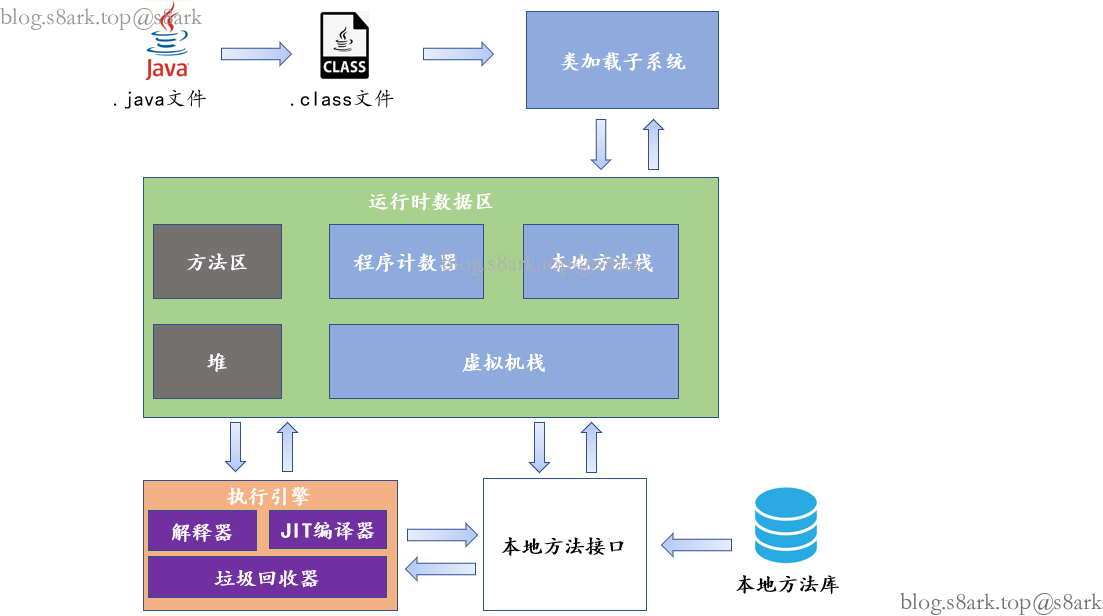
- 方法区和堆是多线程共享的(标为灰色)
- 其他三个是每个线程都有单独的(标为蓝色)
2.类加载子系统
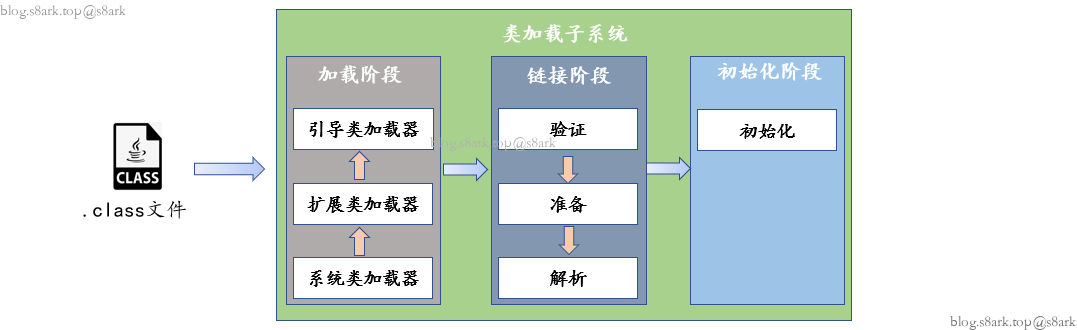
- 验证:验证待加载的class文件是否正确
- 准备:为static变量分配内存并赋零值
- 解析:将符号引用解析为直接引用
常见类加载器
- 引导类加载器(BootstrapClassLoader)
- 自定义类加载器(继承实现了ClassLoader类)
- ExtClassLoader
- AppClassLoader
- WebAppClassLoader
类加载器加载的目录
- BootstrapClassLoader : jre/lib
- ExtClassLoader : jre/lib/ext
- AppClassLoader : classpath
双亲委派机制
双亲委派机制:如果一个类加载器收到了类加载请求,它并不会自己先去加载,而是把这个请求委托给父类的加载器去执行,一直向上委托,如果不能加载再向下返回。
1 | //ClassLoader类 |
那么怎么知道父类是谁呢?在构造Launcher对象时,就给AppClassLoader设置好了parent
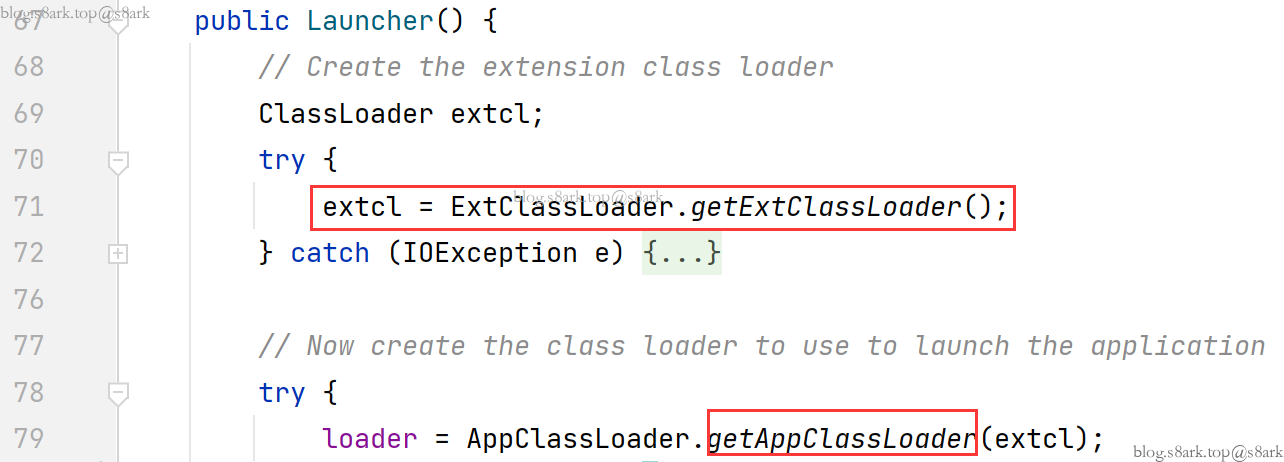
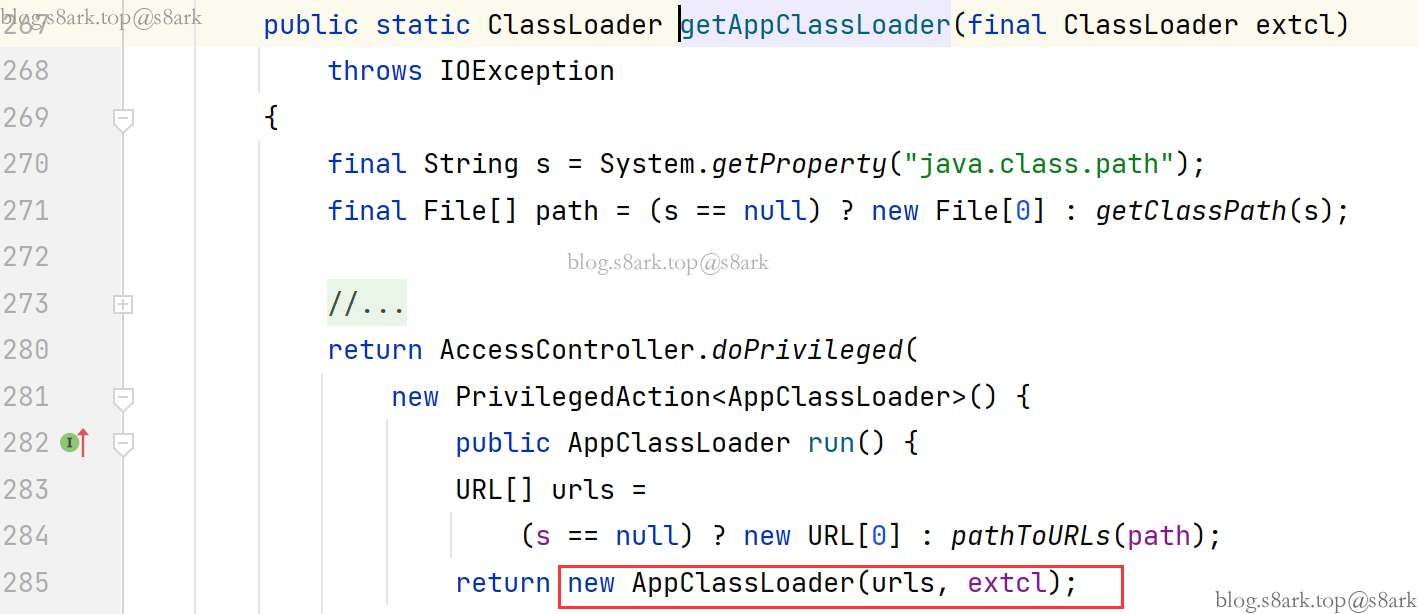
在构建AppClassLoader对象时调用了父类的构造方法





一直到ClassLoader类中,设置了parent
双亲委派机制的作用:
- 避免类被重复加载
- 防止核心API被篡改
Tomcat自定义类加载器
为什么tomcat要自定义类加载器:
若多个web应用拥有同名的类,AppClassLoader 只能加载一个(JVM判断类是否被加载的逻辑为:类名+对应的类加载器实例)。而WebappClassLoader 会为每个应用生成单独的类加载器实例,实现了类加载的隔离。
3.运行时数据区
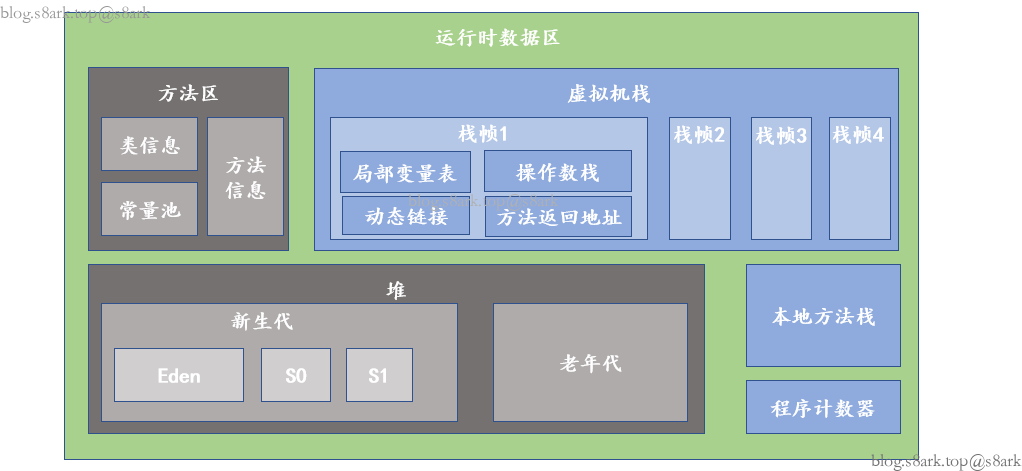
程序计数器
- 它是每个线程私有的,用于存储指向下一条字节码指令的地址
- 不会发生内存溢出
虚拟机栈
- 每个线程有一个虚拟机栈
- 每个方法执行都会创建一个栈帧然后入栈
- 方法执行完毕会从虚拟机栈中出栈
- 线程太多的话,创建了太多的虚拟机栈,会导致OutOfMemoryError
- 方法调用层次太深的话,创建了太多的栈帧,会导致StackOverflowError
虚拟机栈中的每个栈帧包含四个部分:
- **局部变量表(Local Variable Table)**是一组变量值存储空间,用于存放方法参数和方法内定义的局部变量。局部变量表的容量以变量槽(Variable Slot)为最小单位,Java虚拟机规范并没有定义一个槽所应该占用内存空间的大小,但是规定了一个槽应该可以存放一个32位以内的数据类型。引用自[此](Java虚拟机—栈帧、操作数栈和局部变量表 - 知乎 (zhihu.com))
- **操作数栈(Operand Stack)**也常称为操作栈,它是一个后入先出栈(LIFO)。
- **动态连接(Dynamic Linking)**是将要调用的方法的符号引用转化为其在内存地址中的直接引用。
- 方法返回地址一般来说,方法正常退出时,调用者的PC计数值可以作为返回地址,栈帧中可能保存此计数值。而方法异常退出时,返回地址是通过异常处理器表确定的,栈帧中一般不会保存此部分信息。
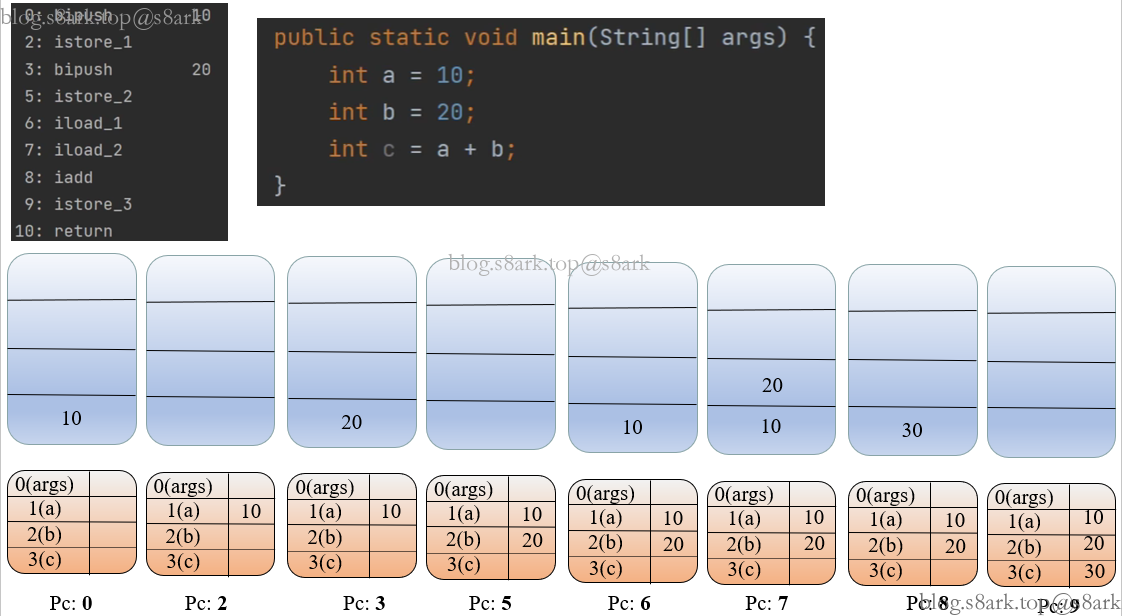
举一个例子:
图中为执行指令时操作数栈和局部变量表的变化
本地方法栈
本地方法栈是jvm的一个组成部分,它用于存储本地方法的调用信息。本地方法是用其他语言(如C或C++)编写的方法,通常用于与操作系统交互。本地方法可以通过Java Native Interface (JNI)或Java Native Access (JNA)来调用。每个新线程都会分配一个单独的本地方法栈。不同的jvm实现可能有不同的方式来处理本地方法栈和Java栈,有些可能共享同一区域,有些可能分开。
堆
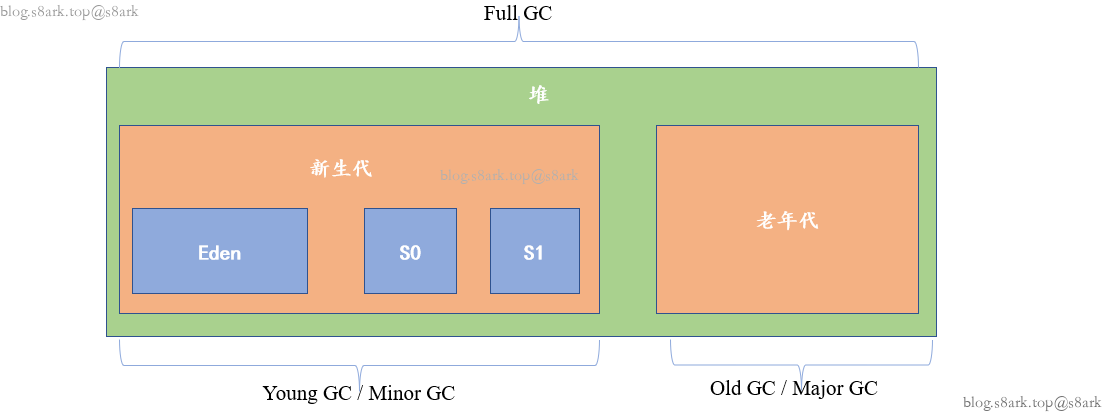
- JVM中的堆是用来存储对象和数组的内存区域
- JVM堆的大小可以通过**-Xms和-Xmx**参数来设置,其中-Xms表示堆的初始大小,-Xmx表示堆的最大大小
- JVM会定期执行垃圾回收(GC)操作,来清理不可达和即将回收的对象,并释放内存空间。
4.垃圾回收
目的:防止内存泄露和内存溢出等问题。
回收的对象: 不再被程序使用的对象,也就是没有被引用的对象。
回收过程:
- 标记垃圾对象:引用计数法,可达性分析法
- 垃圾回收: 标记清除法,复制算法,标记整理算法……
引用计数法
每个对象都保存一个引用计数器属性,用于记录对象被引用的次数
优点:实现简单,实时性好
缺点:无法处理循环引用 (两个或多个对象互相引用,形成一个环)
可达性分析法
JVM会从一组称为“GC Roots”的对象开始,遍历所有可达对象,并将无法到达的对象标记为垃圾对象。
JVM将下列对象视为GC Roots:
- 虚拟机栈(栈帧中的本地变量表)中引用的对象
- 方法区中类静态属性引用的对象
- 方法区中常量引用的对象
- Native方法中JNI引用的对象
- 等等
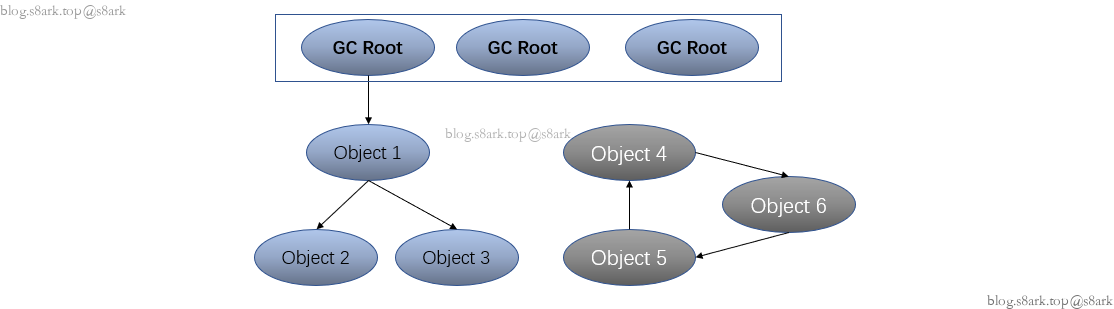
如图所示,蓝色的为可达对象不会被回收。灰色的为循环引用,不能从GCRoot到达。
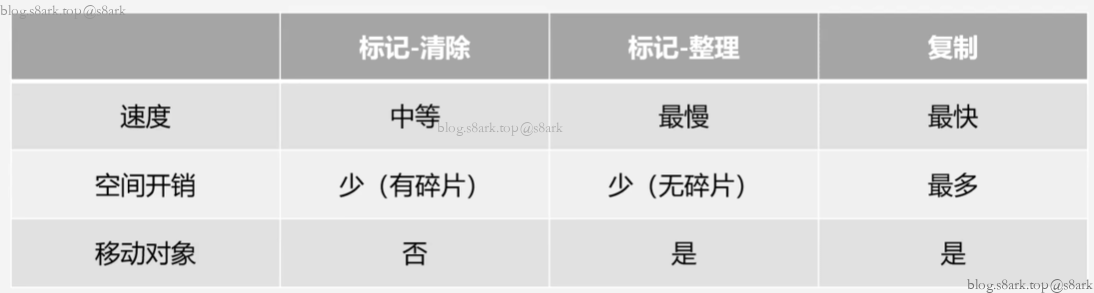
标记-清除算法
- 标记: Collector从GCRoot开始遍历,标记所有被引用的对象。
- 清除: Collector对堆内存从头到尾进行线性的遍历,如果发现某个对象在其Header中没有标记为可达对象,则将其回收。
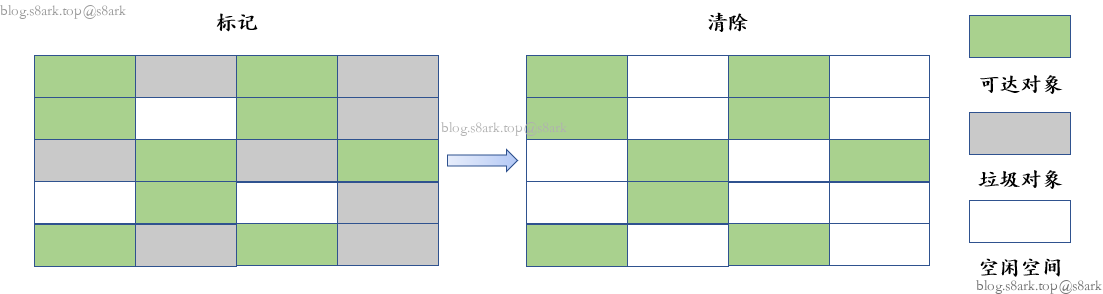
缺点:
效率不算高
在进行GC的时候,需要停止整个应用程序,导致用户体验差
产生大量内存碎片
复制算法
将内存空间分为A、B两块,每次使用一块,垃圾回收时遍历一次目前使用的内存A块,将所有可达对象复制到B块。然后清除A块所有对象,下一次回收再从B复制到A,交换着来。
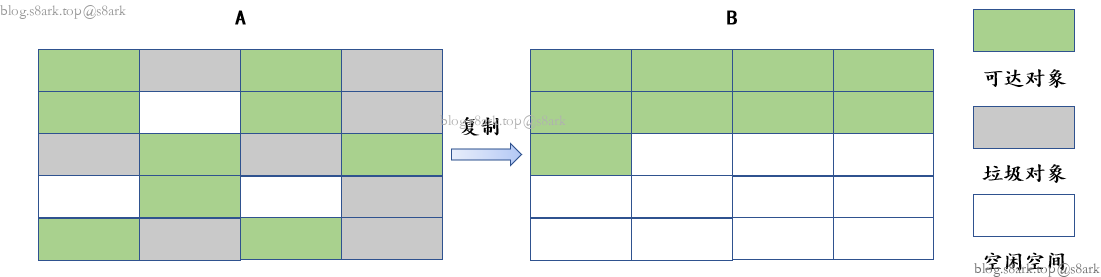
优点:
- 没有标记和清除阶段,通过GC Roots找到可达对象,直接复制,不需要修改对象头,效率高
- 不会出现内存碎片
缺点:
- 需要更多的内存,始终有一半的内存空闲
- 对象复制后,对象存放的内存地址发生了变化,需要额外的时间修改栈帧中记录的引用地址
- 如果可达对象比较多,垃圾对象比较少,那么复制算法的效率就会比较低,所以垃圾对象多的情况下,复制算法比较适合。
标记-整理算法
- 标记可达对象
- 移动可到对象到内存的一端
- 清理边界外的空间

优点:
- 不会出现内存碎片
- 也不需要利用额外的内存空间
缺点:
- 效率要低于标记-清除算法、复制算法
- 也需要修改栈帧中的引用地址
图片来源:https://www.bilibili.com/video/BV1he4y1e7nW?p=23&vd_source=08ec27c446c7fe3ce7235d101b3cbf17
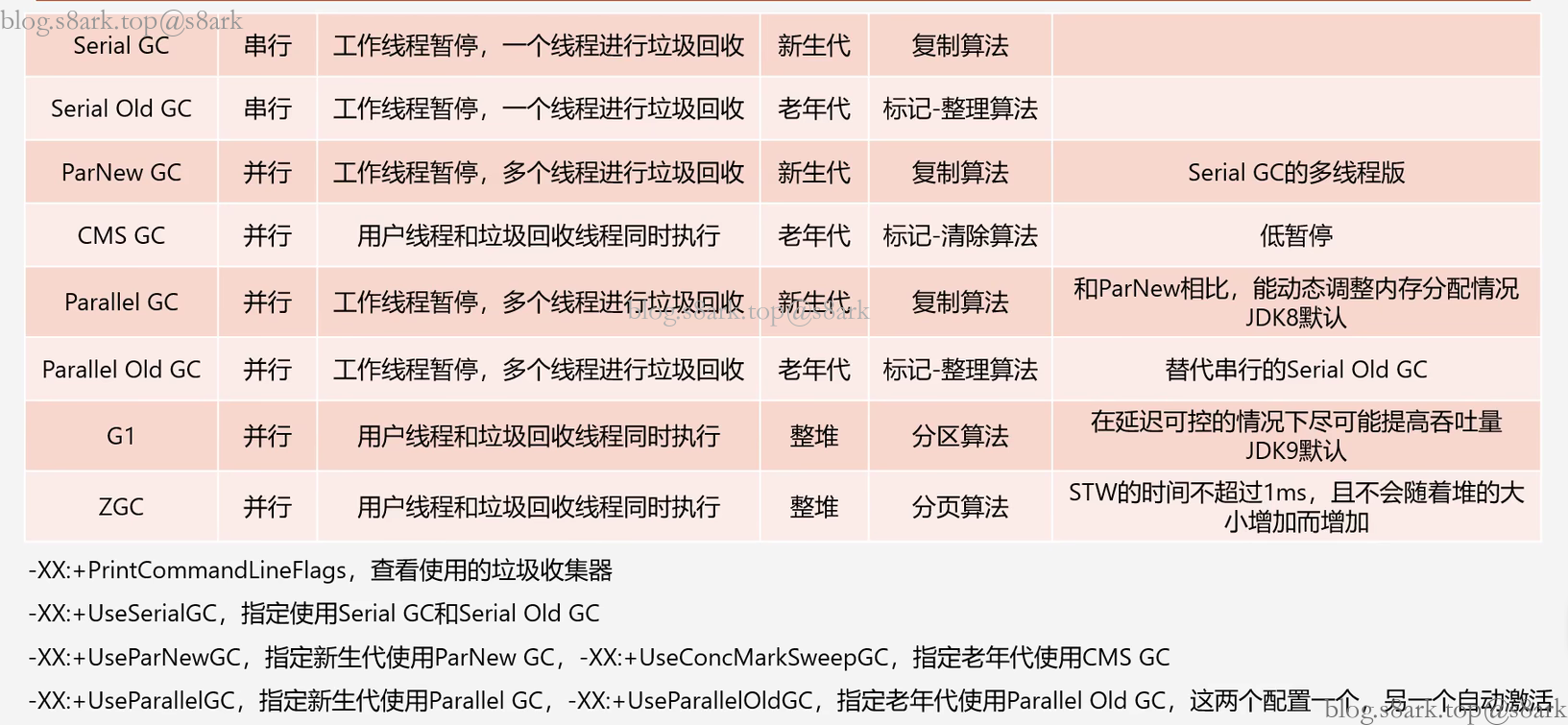
常见的垃圾回收器
图片来源:https://www.bilibili.com/video/BV1he4y1e7nW?p=23&vd_source=08ec27c446c7fe3ce7235d101b3cbf17
 wechat
wechat